|
Abstract:
This paper provides a proposal concerning the
development of a computerised text corpus in Kurdish. After reviewing the
recent development of computer corpus linguistics and lexicography and
providing several examples as dictionary building, concordancing, and
historical language studies, the author gives a short landscape of the
evolution of the computer tools available to Kurdish language and then suggests
the realisation of an experimental corpus of 100 000 words through a
non-commercial consortium as a preliminary to the realisation of a more
important corpus of one million words. Then the paper abstracts the benefits
which would result for Kurdish language from entering this research field.
Keywords:
Computational
linguistics, text corpus & corpora, Kurdish language.
The author:
Gérard Gautier, born in
1955. Originally a physicist, holds a Ph.D. in Anthropology, two MA, in
Educational Science and Computer Science. He studied Kurdish in Paris, worked in
multilingual computing and applied research in computational linguistics
(generation of electronic dictionaries for vocal dictation for IBM). He taught
in university and lived in Taiwan from 1989 to 1996 and in Kurdistan from
1999 to 2004, before coming back to France to work in the field of
science non-formal education for youth and pedagogic consulting.
Computerised
text corpus in Kurdish
A proposal for the Erbil Symposium, September 2006
ggautierk@online.fr
The
development of computer corpus lexicography
Computer
can be used as a tool to build large sets of texts in a specific language,
called “text corpus” (pl. “text corpora”).
This practice has developped more and more during the last twenty years, and
now the construction process and the choices at stake are quite well-known.
Why
did this practice develop ? One of the answers is that the use of computers
more and more permeates all aspects of life, and electronic texts become more
and more available. Another reason is that researchers quickly understood that
those electronic texts can be used in a very interesting way for revealing
useful facts about the language, because it is much easier to search a text on
a computer than on paper.
Building
dictionaries
One
good example is the construction of dictionaries.
Before
the use of corpora, the dictionary author or “lexicographer” resorted to
reading large amount of texts and introspection to find facts. The team who
built the well-known Oxford English Dictionary (OED) in the 20s pushed this
technique to the extreme by using hundreds of voluntary workers in the whole United
Kingdom.
They scanned publications to look for interesting ways of using words, then
they sent the data on small slips of papers to a centralised office in Oxford,
where it was put in order for inclusion in the dictionary. This process took
years.
Today,
the OED would probably be built using a text corpus. It is the way the Cobuild
Dictionary was built in the 80s.
Twenty
years ago, in the 80s, a set of texts counting one-million words, as the Brown
University Corpus, was seen as a big corpus. In 1993 it was already
considered small. Now, it is considered very
small, and ten-million words corpora are quite common. Indeed the Cobuild
corpus now counts hundred of millions of words, 56 millions of which are
currently available on the Internet through Collins WordbanksOnline
service.
Concordancing
A
now quite classical example of the use of text corpora is the concordancer.
This small piece of software allows to find all the occurences of any word in a
text. It produces outputs called KWIC, ie. “Key Word in
Context”, very useful
to look quickly at different usages of any word or expression. Below is a
concordance of the word “newspaper” in the
Collins WordbanksOnline
English corpus, obtained directly online from the Collins Corpus Concordance
Sampler website.
| Iraqi withdrawal. An Iraqi government | newspaper | (al-Thawra) has said that a new United
| | mother was a journalist. After her | newspaper | office was ransacked she was jailed - for
| | for Aamulehti, Finland's second largest | newspaper | and the secretary of Finland's Electrician'
| | Hunter and Julian Amery. The Observer | newspaper | subsequently revealed Lauder-Frost's racist
| | top of the 10 note. Finally, a folded | newspaper | would be laid carefully over the cash and
| | Long may it continue. [p] In the world of | newspaper | publishing, there is one success story that
| | in a less hostile climate. The TODAY | newspaper | agrees, saying that if Iran's dead could
|
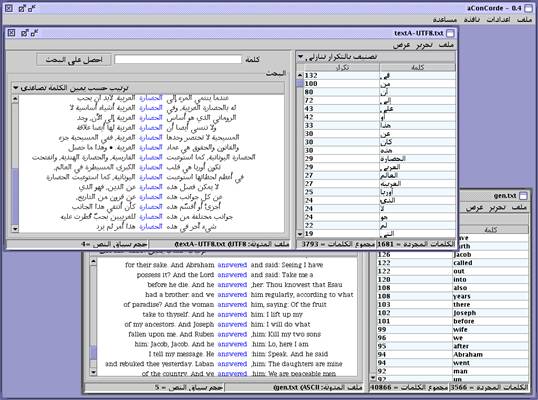
Concordancing tools are
now available for Arabic, which could be used for Kurdish in Arabic letters as
well. A good example is aConCorde, developped by Andrew Roberts at the School of Computing of
University of Leeds (UK) (see screenshot below).
|
|
|
A
screenshot of aConCorde © from Andrew Roberts website
|
The
figures near the words in the lists on the right (both Arabic and English) are
the number of occurrences of each word. It shows that another possible
use of text corpora and concordance is in teaching language.
Specifically, teachers of a second language found quite useful to have students
use concordancers in class to investigate facts – and know the words with
highest frequency.
An
example of historical study
Corpora can also be used
for other studies, as ascertaining the evolution of the language. If texts are
ordered by date, it becomes possible to see how the use of a given word evolves
over time. For instance, the French National Centre for Research (CNRS) and University of Chicago teamed to
give access to a large corpus of 150 million words of French texts through the
ARTFL project (American and French Research on the Treasury of the French
Language).
To quote from ARTFL website :
“The ARTFL database is one of the largest
of its kind in the world. The number, variety and historical range of its texts
allow researchers to go well beyond the usual narrow focus on single works or
single authors. The database permits both the rapid exploration of single
texts, and the inter-textual research of a kind virtually impossible without
the aid of a computer.”
In Standford University, Keith Baker was able to use ARTFL to
study the evolution of the use of the word “revolution” across the centuries
spanned by the texts. In the resulting publication where the author wrote about
the usefulness of ARTFL corpus to his research :
Over the years, I have used
ARTFL in a number of research projects on the history of French political
culture. [...] I have found it extremely helpful. Generally speaking, I have
searched the database for occurrences of terms relevant to particular political
concepts. The searches [...] have demonstrated shifts in the frequency of the
uses of important terms in the database over relatively long periods of time.
[...]
Another project in which I had valuable recourse to ARTFL
was a study of the idea of "revolution" in prerevolutionary France,
first published in 1988 and also reprinted in Inventing the French Revolution.
Searching the database for révolution produced an enormous amount of
information. It revealed important occurrences in works I would not otherwise
have investigated, as well as ensuring that I did not miss occurrences in works
I already knew to be crucial [...] .
Given
the high speed evolution Kurdish language is witnessing in Kurdistan Region of
Iraq, it is a likely useful use for an eventual text corpus.
Kurdish
particulars : a quick evolution of the available tools
Quite a decade ago, I
worked on the technical difficulties awaiting the researcher trying to build a
Kurdish language corpus . At the time, tools as
well as standardisation were lacking, but fortunately, now, if some technical
choices indeed remain, the “technical landscape” has
simplified a lot. First, operating systemes with an efficient Arabic Language
Graphic User Interface (Arabic GUI), once only available on MacIntosh, have
generalised inthe PC world. Second, the UNICODE multilingual encoding scheme,
since introduced in the 90s, has gained wide acceptance, particularly thanks to
the Internet (in Kurdish, this gave rise to the creation of numerous websites
using UNICODE, the majority of which were not online even 5 years ago).
This evolution means
that whatever representation we chose for Kurdish – Arabic or Roman alphabet –
we now have the tools to work, as the majority of functions which are
accessible to Arabic should work with Kurdish in Arabic letters. Besides, the
prevalence of UNICODE means that we now have a natural standard to rely on to
store any textual data in Kurdish. Some Kurdish groups abroad started to make
specific tools available, particularly the KurdIT Group .
Starting
the tests for a Kurdish Text Corpus
There are obviously
several possible choices as to the building of a Kurdish language text corpus,
but I would like to suggest one of them.
First a “small” experimental
corpus of 100 000 words should be built to test the technical problems.
This is only an introductory paper, so I will not enter into more technical
considerations : there are still some remaining problems, as the existence
of some faulty computer fonts which oblige the user to type the short vowel e
as a h followed by a non-separating space... According to the software
under which they were typed and the font used, the texts collected may have to
be “normalised” (i.e. those
sequences of h + space replaced by e) before being
exported and re-coded into UNICODE. There are also some small problems
concerning the encoding of the sequence [lam + alif] لا and [lam + hawt + alif] لاَ. A small set of texts would allow to think to the problems as
they occur, and test-drive the solutions for a bigger project.
Then... since the
beginning of the 90s, the Kurdistan Region of Iraq witnessed an important
development in the field of publications. The language itself evolved quite a
lot during the last 10-15 years. I think that a bigger corpus (but still small
by todays standards) of one million words could gather papers taken from
all the magazines published since this time.
I
think it is magazines which capture the best the introduction of new vocabulary
in the language. By this I do not mean at all that other types of texts should
be excluded. I think that, to produce a balanced corpus, daily newspapers and
books should indeed be included, with papers from different fields.
Another
aspect, which should not be forgotten, is the legal one. It is very important
that the authors and publishers of any text, non only give thir texts to the
project, but also specify in written form the right of use of their
texts for inclusion into the corpus. A non-commercial use agreement should be
prepared, which will allow the distribution of the corpus by official research
agencies in the world to all university departments interested, for a nominal
fee. Missing such an agreement, the texts could not be distributed for
research.
Benefits
They
are numerous and I will only abstract them.
If
the result of the work can be distributed through a linguistic research agency,
for instance ELRA-ELDA in Europe, the
availability of Kurdish data will encourage researchers in whole Europe – including
Kurds in diaspora – to work on the language. It will increase the global
presence of Kurdish in the linguistic research field in the world, hence defending
the language in general (and also defending it against scientifically unfounded
allegations that there would not be anything as “Kurdish language”...). A known
example of this effect is Korean. The availability of electronic resources in
this language actually produced a sharp increase in the number of studies
devoted to it.
There
are new techniques to learn in the process, as similar experiences have been
gone through by numerous researchers. It will allow Kurdish
researchers to link with a whole community abroad. Besides, this work will
boost the reflexion on standardisation and will probably help making choices,
also for future computer software development as fonts and keyboard
drivers encouraging good typing practice by users. This might look
like not very useful, but if we want one day a correcting dictionary for
Kurdish, working under any word processor, it is necessary to first have good
typing tools !
And
indeed, the availability of a large quantity of electronic data in Kurdish
means that it will become possible in time to generate correcting tools as are
common in Arabic or English. And the existence of such tools in turn is
important in the day-to-day defence of any language.
Then
other applications will become possible, as a Wordnet in Kurdish, and more
generally the generation of databases following XML standards, which will help
a lot the publishing of – online, electronic or even paper – dictionaries,
general or specialised. This is a necessary development to move forward in
translation work, which is necessary for further academic research, but also
business and economy in general.
Conclusion
The
institutional support for such a project might be a consortium headed (for
instance) by a computer department, including any interested institution and
specifically publishers willing to donate their files under a non-commercial
agreement. It would provide a framework for MA students willing to work on this
project.
Corresponding members to help them could be
situated in academic institutions abroad, to cooperate with the consortium and
providing link with similar research in the world. Contacts to this effect
could be made with laboratories and universities known to work in the field.
Besides the most known labs working in “big” languages as English, numerous
“small” language speakers, as Catalan, Britton, Gaelic, now work on such
developments. Kurdish is not alone in this problematic, and as already
mentionned, starting this type of work would provide a link with all those
people sympathetic to Kurdish needs.
(*) ggautierk@online.fr, +33 6 73 26 11 13
| 
